
This article was originally published on QBox’s blog, prior to Cyara’s acquisition of QBox. Learn more about Cyara + QBox.
Wondering how to fix your Microsoft LUIS chatbot?
Testing and fixing a Microsoft LUIS chatbot can be very time consuming. Where is it going wrong? Are my chatbot fixes working? Why are my fixes now causing other problems? Is there a way of continually monitoring my chatbot’s performance?
Cyara helps organizations regain visibility and control over the chatbot development lifecycle with automated testing and monitoring solutions.

This guide takes you right from inputting your training data right through to drilling down into why utterances and intents aren’t working—and, of course, how to put them right.
What you’ll learn:
- Testing Microsoft LUIS data
- Improving correctness and confidence—the key KPIs
- Intent scoring and upgrading
- Individual intent and utterance analysis
- Validating fixes and checking for regressions
- How to use our additional features
- Tracking improvements to your model
If you’re looking for a guide rich in detail and with lots of practical guidance, it’s worth giving this one a watch.
Watch the video here:

We hope you found the video useful. If you have any questions about how you can improve your NLP chatbot, contact us. We’d be happy to show you what our solutions can do!
Great strides have been made in the advancement of NLP systems, but chatbot trainers still face one fundamental challenge: how to get an NLP model to perform at its best.
Understanding NLP Working Principles
First thing’s first: NLP doesn’t “read” and “understand” language and conversations in the same way humans have learnt to read and understand them.
It’s easy for chatbot trainers to fall into the trap of believing that just because an utterance makes sense to them, their model will understand it with clarity and identify the correct intent with confidence.
NLP engines such as Lex, Dialogflow, and Rasa need a qualitative approach to the training data.
You can imagine the way they work as transfer learning (this is a machine-learning method that takes a previously trained piece of information and reuses it as the basis for learning a similar piece of information).
Simply adding more and more training data to the model is not the best way to solve any weaknesses in chatbot performance.
In fact, this is more likely to result in poorer performance. It’ll add too much diversity, it’ll overfit or even unbalance your model, and it’ll probably become ineffective as a result of being trained on too many examples.
Carefully curated training data is one of the key attributes of good performance. But more importantly, chatbot trainers need to understand what the learning value is of each utterance they add to their model.
The optimum number of utterances is very difficult to pinpoint, because it’ll depend on a number of factors such as other intents, their “subject closeness,” their number of utterances, and so on.
But as general guidance, a good starting point is 15 to 20 utterances—but start to be cautious when you reach the 50- or 60-utterance mark.
How Can You Influence NLP Performance?
Broadly speaking, there are two categories of NLP engine:
- The ones with maximum control, where you can tune almost all parameters, control where the data is, etc. These are great, but only hard-core data scientists and development teams will make the most of them.
- Such engines also require you to manage the tech stack, and do the upgrading, scaling, and hosting yourself. Rasa is one example of this category of engine.
- The ones for minimum investment, provided by the most renowned NLP providers, where you benefit from the latest and most innovative advancements and improvements in NLP.
- The only influence on performance is your training data. This category of NLP engine includes LUIS, Lex, Watson and others.
Whichever NLP engine you choose to use, your training data is key to unlocking performance.
So, you are inevitably going to wonder how to maximize the impact of your training data by asking questions such as:
- Should I repeat this concept twice?
- Is five times too many?
- Would three times be the optimum amount to gain maximum learning power for my model?
- How many concepts can I cover in one intent before the intent is deemed too wide?
- How should my utterances be structured?
- Should they be as short as possible—or longer, to cover more meaning? How much variance should I give to each utterance?
An experienced chatbot trainer will know the answers to all these questions if they have a true understanding of the influence and learning value their training data has on their model.
And to do this, they use techniques to measure those performances.
How Do You Measure the Quality of Your Training Data?
Your training data needs to be assessed and analyzed to measure its quality. So, techniques like preparing test data (also called cross-validation or blind data) are very efficient, but also time-consuming.
K-fold is not great when you build your model because the changes in the training data will create performance changes only due to the randomisation element of the K-fold algorithm. Leave-one-out is another technique I invite you to investigate.
Ultimately, you need to find a systematic way to measure your model.
Understanding the “ripple effect” is very important. The ripple effect is what happens when you modify some training data in an intent X, and you improve that intent, but the performance of other intents (A, D, F) also changes, sometimes for the better—but sometimes not.
The ripple effect is due to the fact that intent-classification models tend to rely on a set amount of training data per intent and this means that each piece of training data has more influence.
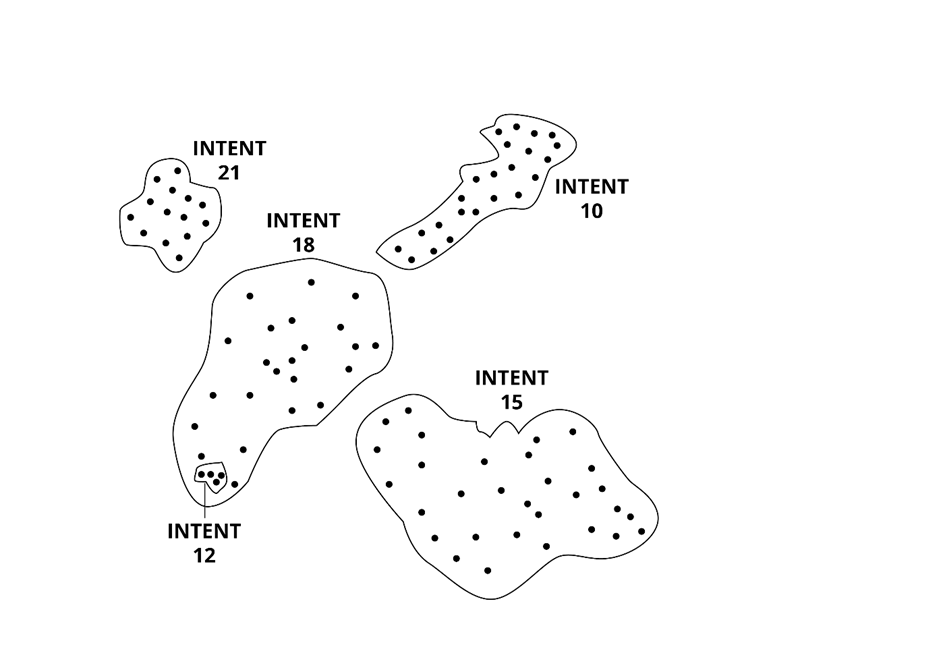
The diagrams below illustrate the ripple effect, and in particular, the positive and negative effect some changes can make.
In figure 1, intent 18 is struggling to perform well. It is confused with the training data of intents 10, 15 and 21. We can see that the training data (represented by dots) is spread out, indicating that the definition is not well understood.
In figure 2, we reworked the training data and improved intent 18. We can see that the definition of that intent is narrower.
By improving intent 18, we’ve removed some confusions in intents 10, 15 and 21, even though we didn’t change their training data, so their performance has improved (a positive ripple effect).
However, if you look at intent 12, which did perform well in figure 1, it is now confused with intent 18—this is an example of a negative ripple effect.
Figure 1:

Figure 2
These types of analysis are only possible with systematic testing. Finding a technique that works for you—leave-one-out, or test data, or a tool will dramatically improve your understanding of the performance of your model, and help you find weaknesses, analyze the reason for those weaknesses, and validate your fixes.
Still have questions? Contact us today!



